
实验数据处理分析测试的特点(一)
发布时间:2017-09-01
分析测试是一个获取分析对象化学组成和结构信息的过程,为工农业生产、国内外贸易、科技发展和社会进步提供大量准确可靠的分析检测数据,作为正确评价科技成果、保证工农业生产和国内外贸易正常进行的基础技术资料。为了获得准确可靠的分析检测数据,必须了解整个分析测试与从分析测试数据提取信息的过程及其特点。化学分析和大多数仪器分析的特点大致可以归结为:分析过程具有复杂性;分析测试数据具有统计波动性;抽样检验是基本的分析测试方式。
与物理测量相比,化学分析和大多数仪器分析过程都比较复杂,包括采样、样品前处理如溶(熔)解、消化、分离或富集、测试等多个相互联系的环节,分析测试结果受到多种因素的影响,涉及抽样的代表性和来自基体的影响;可能发生的样品损失、沾污;样品制备和测量方法引入的人为操作、测试方法和仪器误差等。分析测试过程中任何一个环节的失误,都将对测试结果产生重要影响,甚至导致一次测试的完全失败。
由于分析测试过程的复杂性与影响因素多,而各因素的影响又难以完全控制,从而导致在同样条件下测得的数据参差不齐,有时表面看起来似乎有点“杂乱无章”。从测定误差的角度考虑,测定量值是一个以概率取值的随机变量,不可避免地要受到随机误差的影响,有时又要受到系统误差的影响,使得测定量值具有统计波动性。分析人员若不采用科学的方法去分析和处理这些参差不齐、表面看来似乎是“杂乱无章”的测试数据,就无法发现寓于其中的统计规律性,进而引出符合客观实际的科学结论。由此可见,数据统计处理是整个分析测试过程不可分割的一部分。
在相当多的情况下,被分析的原样品不能直接上机测定,需要对原样品进行预处理,将原样品转变为适合于某种分析仪器测定的试验样品(试样)。这就是说,被分析原样品在上机测定之前已受到破坏,原样品分析完之后不复存在,通过分析测试数据对直接测定的试样本身做出结论已经没有什么实际意义。测试样品的目的只是通过测试样本(试样),获得有关样本(试样)的信息,由样本信息以一定的置信度去推断和估计测试样本(试样)所来自的总体(原样品)的特性。比如用原子吸收光谱法检查一批出El猪肉罐头的含铅量,当测得猪肉罐头的铅含量之后,作为直接测定试样的猪肉罐头已受到破坏,已不能再作为商品出售。测定其中含铅量的目的,是从它的含铅量去估计和推断“罐头样品”抽样的那一批出口猪肉罐头的含铅量是否合格。由于仪器分析在大多数情况下是“破坏性”分析,决定了仪器分析采用的基本方式是抽样检验。
由于仪器分析采用的基本方式是抽样检验,要通过对试样的测试去了解和获得有关分析总体(原样品)的定性、定量、形态和结构等方面的信息,对原样品的品质属性做出科学的结论。要做到这一点,至少要解决3个基本问题:①所抽取的样本对总体有足够的代表性,为此要采用科学合理的方法抽样和取样;
②对样本的分析测试结果(数据、图谱等)是可靠的,为此要求在整个分析测试过程中实施严格的质量控制;③由样本信息推断总体特性时,必须遵循科学的推理方法。这3个基本问题的解决都离不开分析检测数据的科学处理。
一、分析测试数据统计处理基础
在分析测试中,测定量值是一个以概率取值的随机变量。而在大量重复试验中得到的测定量值具有统计规律性,测定量值的概事分布遵循正态分布,其期望值为E(χ)=μ,方差为D(χ)=σ2。正态分布的概率密度函数为:
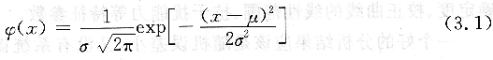
记为N(μ,σ2)。由式(3.1)可以看到,当μ和σ已知,概率分布就完全确定了,给定任一的χ值,就可以确定该χ值出现的概率。这就是说,全部测定量值的概率分布可以用岸和口两个基本参数来表征它。μ确定了概率分布中心在χ轴上的位置,表征测定量值的集中趋势,σ表示测定量值沿χ轴的散布,表征测定量值的离散特性。正态分布是大量观测所得到的测定量值的理论分布曲线,但在实用上,当测定量值数目大于30时,通常可用正态分布近似描述测定量值和测量误差的分布特性。在有限次测定中,人们不可能获得总体的平均值肚和标准偏差σ,但可以得到样本的平均值χ和样本的标准偏差s。如果样本平均值χ和样本标准偏差s能够充分近似地代表总体平均值μ和总体标准偏差一,那就可以用样本平均值z和样本标准偏差s来表征全部测定量值的分布特性。
现在的问题是χ和s是否能充分近似地代表μ和σ。数理统计理论已经证明:在等精度测量中,样本平均值χ是一组测定值中出现概率最大的值,是μ的无偏估计值和具有最小方差的最优估计值,样本方差s2是σ2的无偏估计值,用χ和s来分别代表参数μ、σ时没有系统误差;在不等精度测量中,样本加权平均值χ。是一组测定值中出现概率最大的值,是μ的无偏估计值和具有最小方差的最优估计值,样本加权平均值标准偏差sW是σ的无偏估计值。因为样本平均值χ和样本标准偏差s能够充分近似地代表总体平均值“和总体标准偏差一,所以,在分析测试中,常用样本平均值和样本标准偏差来报告分析检测结果。
前面曾经指出,测定量值具有统计波动性。在正常的情况下,测定量值统计波动的程度应该是多大?按照数理统计理论,各个测定量值出现的概率遵循正态分布,由式(3.1)可以计算测定量值落在2倍标准偏差之外的概率小于5%,落在3倍标准偏差之外的概率小于0.3%。由2倍标准偏差或3倍标准偏差所构建的区间,即是分析测试中所允许的合理误差范围。这个合理误差范围为分析人员判断和取舍分析数据、评价数据的可靠性与分析结果溯源提供了理论依据。
二、评价分析方法和分析结果的基本指标
一个好的分析方法应具有良好的检测能力,易获得可靠的测定结果,有广泛的适用性。此外,操作应尽可能简便。检测能力用检出限表示,测定结果的可靠性用不确定度表示,适用性用校正曲线的线性范围和抗干扰能力来衡量。因此,在评价分析方法时,应给出方法的检出限、用该法测定某一或某些特定成分的不确定度、校正曲线的线性范围、抗干扰能力等特征参数。
一个好的分析结果应该是随机误差小,又没有系统误差。随机误差影响测定结果的精密度,用标准偏差或相对标准偏差表征。系统误差影响测定结果的准确度,用误差或相对误差表征。获得一个同等精密度和准确度的分析结果,对不同的分析人员所花费的劳动是有差异的,所花费的代价用测定次数表征。因此,为了科学地评价一个分析结果,在报告分析结果时,应该给出测定平均值、标准偏差、误差(在不存在系统误差时不给出)和测定次数等基本参数。
1、检出限和灵敏度
检出限是指能产生一个确证在试样中存在被测组分的分析信号所需要的该组分的最小含量或最小浓度。在测定误差遵从正态分布的条件下,指能用该分析方法以适当置信度(通常取置信度99.7%)检出被测组分的最小量或最小浓度。最小检出量和最小检出浓度可由最小检测信号值与空白噪声导出,分别以qL和cL表示:

参考资料:现代仪器分析实验与技术






